
Problematikou ukládání dat se v praxi zabývám více než 10 let, a jako koníček mi to bylo v podstatě od základní školy, kdy jsem na disketách (FAT) kamarádům vytvářel kružnice místo stromů a tropil další hlouposti. A přibližně těch 10 let mi v hlavě leží myšlenka na dokonalý systém souborů. V podstatě od té doby, co jsem si poslechl první přednášky o ZFS.
Než se pustíme do popisu toho, jak by podle mě měl být FS postaven, ukažme si několik příkladů. Postupně asi bude více jasné, z jakého základu moje myšlenka vychází. Omezuji se pouze na FS s podporou více diskových zařízení, staré jednoduché fs nad jedním diskem už jsou pro mě v podstatě pasé.
ZFS
Začněme hned tam, kde moje myšlenky na dokonalý fs začaly. U ZFS. ZFS je velmi vyspělý fs, který umí použít více diskových zařízení, umí se vypořádat s výpadkem disků a to hned v několika modech. Jak jsem psal již v dřívějším článku, ZFS řeší redundanci na úrovni vdevů:
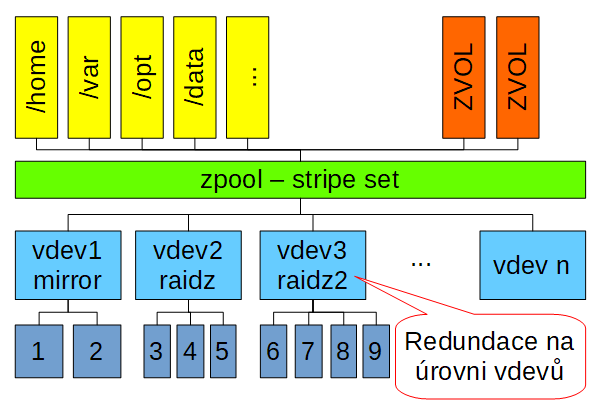
V ZFS jsou disky spojovány do vdevů (typu single, mirror, raidz), tyto vdevy se následně spojují do zpoolu odkud vyrůstají datasety v podobě fs, nebo zvolů (blokové zařízení).
Bohužel, s vdevy nelze hnout. Pokud začněte s mirrorem (zfs nad dvěma disku s vdev typu mirror) a chcete přidat třetí disk a udělat z toho třeba raidz (odolnost proti výpadku jednoho zařízení, něco jako raid5), nemůžete. Můžete jen přidat další vdev třeba typu raidz (to znamená koupit minimálně 3 další disky). Ani vdev jako celek už nelze odstranit.
Jak jsem psal, ZFS je dobrý FS, ale značně neflexibilní co do dalších změn uspořádání disků.
BTRFS
BTRFS řeší redundanci na úrovni celého fs. O BTRFS jsem toho napsal tolik, že to asi nemá smysl tady opakovat. Pojďme se tedy zaměřit jen na řešení odolnosti proti výpadku disku:
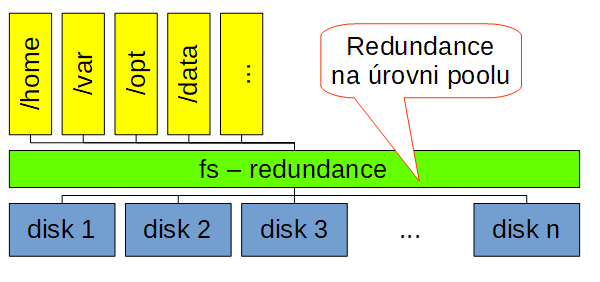
U BTRFS vytvoříte FS s určitou redundancí (aktuálně raid1, raid10), postupně můžete přidávat disky klidně po jednom a staré disky odebírat.
Bohužel, celý fs sdílí jeden typ redundance (který lze ale za běhu měnit), pokud tedy na jednom fs máte důležitá data (pro který třeba chcete raid1) a data, na kterých vám až tak moc nezáleží, takže byste pro ně rádi třeba použili nižší nebo žádnou redundanci, tak toto na btrfs v aktuálním stavu neuděláte.
Oproti ZFS ale BTRFS nabízí lepší flexibilitu co se týče přidávání a odstraňování diskových zařízení. (A v dalších aspektech.)
LVM
LVM není FS, pracuje na blokové vrstvě, ale LVM umožňuje vytvářet LV různých typů (linear, mirror, stripeset).
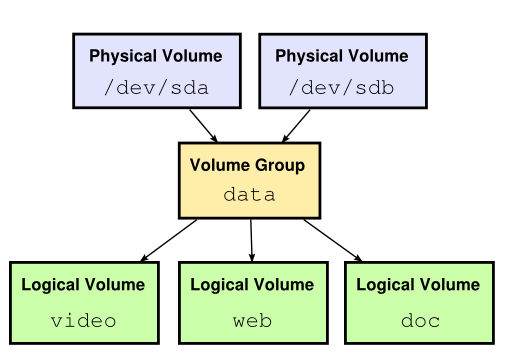
LVM se ale docela blíží tomu, co bych já od FS očekával a proto jsem jej do tohoto článku zařadil, i když se nejedná o FS.
Do LVM vstupují bloková zařízení (disky – PV), jejich bloky se spojují do poolu (VG), nad kterým jsou potom exportovaná bloková zařízení (LV) a to různých typů redundance. Redundanci si tedy můžeme zvolit později, nemusíme ji definovat při zakládání LVM. Což považuji za skvělou vlastnost, ale v praxi se používá pouze minimálně a v praxi mnohem častěji narazíme na to, že jako PV do LVM vstupují bloková zařízení třeba ze softwarových raidů (md).
Můj návrh
Snad už je to z výše uvedeného jasné. Zatímco ZFS řeší redundanci na úrovni vdevů, BTRFS napříč celým FS, tak osobně bych preferovat možnost zvolit si redundanci na úrovni subvolume (datasetů). Vytvořím si subvolume pro důležitá data a zvolím si redundanci třeba odolnost proti výpadků dvou disků. Potom můžu mít data, na kterých příliš nezáleží (snadno je získám znovu) pro ty vytvořím subvolume třeba typu stripe set. Když selže nějaký disk, tak o tuto subvolume prostě přijdu.
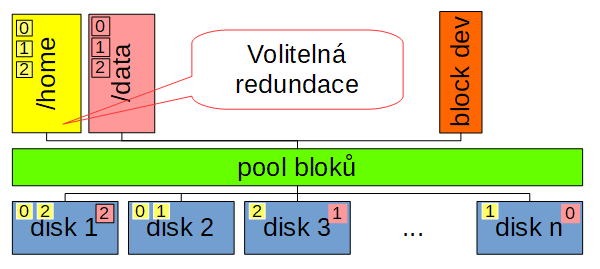
Pochopitelně, dneska v roce 2017 už bych se vůbec neomezoval jen na lokální disky. Disky vstupující do poolu bloků, nechť jsou klidně na síti. Do takového clusteru přidám další disk a zvětší se mi dostupné místo na fs. Odeberu disk a zbytek poolu se přepočítá dle zvolené redundace.
V tomto článku neřeším žádné další vlastnosti FS, jen jsem se chtěl podívat na způsoby řešení redundance v tom kterém systému. Většina FS vychází se starého rozdělení na: hw (disky), řešení redundance (raid, ať již v sw nebo hw), rozdělení blokových zařízení (MBR, GPT, LVM), FS. A většinou řeší redundanci na co nejnižší vrstvě. Což je jistě výhodné, vyšší vrstvy se nemusejí zabývat výpadky disků.
Na druhou stranu to není výhodné pro spoustu dalších vlastností, které bychom od FS dnes očekávali. Dneska automaticky očekávám možnost vytváření snapshoty subvolume. V libovolném množství. Každý snapshot je samostatná subvolume, tedy zapisovatelná a dále snapshotovatelná. Tuto vlastnost BTRFS používám každý den.
Jestli čekáte nějaké šokující odhalení na závěr, musím vás zklamat. V nabídce toho příliš není. Asi nejbližším FS blížící se mým představám je CEPH, který ale nepochopitelně opět řeší redundanci na úrovni celého clusteru a nikoliv jednotlivých blkdev nebo cephfs (i když ten je v clusteru jen jeden, takže z tohoto pohledu je to něco jako distribuované BTRFS), na druhou stranu je velmi flexibilní s práci s disky (OSD), disky můžete přidávat a odebírat kdykoliv potřebujete (s dodržením jistých pravidel a s ohledem na stav nodů). Na druhou stranu nejmenší doporučovaná hodnota redundace je 3 (data jsou v clusteru ve třech kopiích), tedy těch disků budete potřebovat ještě o dost víc než dnes.
Přitom zrovna u architektury CEPH by nebyl problém si zvolit redundanci při vytváření objektů. Ostatně, stejně jako BTRFS by na toto mělo být interně připraveno, protože při změně módu fs jsou na disku bloku s různým data profilem.
Co říkáš na reiser4 a hammer2 ?
Reiser neznám, nikdy jsem nepoužíval.
Hammer2 jde rozhodně dobrým směrem. Multidevice v základu (už hammer 1), tohle má být rozprostřené po síti (jestli to dotáhnou i včetně rozumného ovládání, tak to bude super, tohle je největší bolest CEPHu), nezávislé snapshoty (zapisovatelné, mountovatelné), vypadá to velmi dobře a možná za pár let půjdeme na DragonFly BSD jen pro tento FS.