
Celým detektivním seriálem ([1], [2], [3]) o nepříliš výkonném ZFS na FreeBSD se line jedna myšlenka. Zda náhodou ZFS nebo ioscheduler ve FreeBSD neomezuje rychlost (možná záměrným vkládáním sleep) IO procesu, aby zabránil přetížení systému a nedostupnost dat pro ostatní procesy.
To zcela logicky vede k myšlence, zda by nešlo číst data paralelně ve více procesech. To se snadněji řekne, než udělá. Pokud potřebujeme data rychle zkopírovat jinam, žádné paralelní cp nebo tar neexistuje (rozhodně není automaticky dostupné na běžných systémech).
Čistě pro test jsem si takový paralelní cp napsal (pomocí Python Multiprocesing Pool . map). Je to takové udělátko pro paralelní zpracování pole:
pool = Pool()
pool.map(fce, data)
kde fce je nějaká funkce akceptující argument a data je pole dat (v mém testovacím případě pole souborů). Map spustí fce (v mém případě shutil . copyfile()) nad každým prvek vstupního pole. Pool() tuto běžnou funkci (map, filter, reduce zná asi každý) umí spustit paralelně, ve výchozím stavu v počtu procesů podle počtu procesorů. Parametrem lze počet procesů určit. Tyto nástroje nám umožňují si snadno napsat test paralelního čtení.
Pojďme se, bez dalšího zdržování, podívat na výsledky. Jako testovací dataset posloužil můj pracovní dataset se soubory o velikostech cca 1MB s rozptylem až do 10MB.
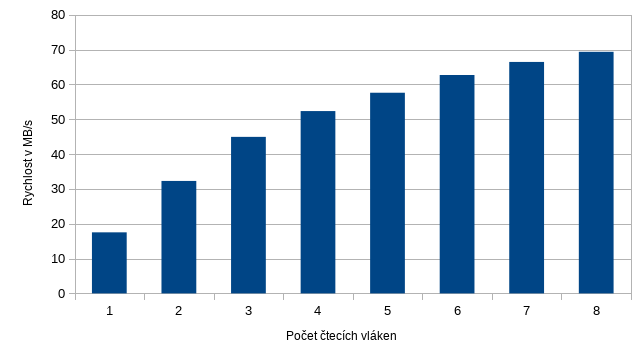
Jak vidíme, test čtení v jednom procesu je pomalý, jen 17.5MB/s. S vyšším počtem procesů rychlost poměrně rychle stoupá a postupně se asymptoticky blíží limitě. Mimochodem, v minulém článku jsem teoreticky vypočítal rychlost čtení souborů o velikost 1MB a dostal jsem se k číslu 75MB/s. Dnešní test čtení ukazuje limitu někde kolem 70MB/s (v datasetu jsou ale soubory různých velikostí s průměrem 830kiB).
No jo, ale co teda s tím? Na jednu stranu je fajn, že se systém běžným používáním nenechá zablokovat a všechny ostatní procesy se ke svým datům dostanou bez ohledu na další provoz na FS, na druhé straně asi není dobré mít k disposici jen cca 25% výkonu v případě, kdy např. potřebujeme zkopírovat pracovní data na jiný disk nebo systém. Jistě, můžeme si napsat speciální nástroje, ale i to má svá rizika (viz varování v dokumentaci modulu shutil) – tzn je nutné řešit speciální soubory, práva, ACL, symlinky a hardlinky, sparse file apod. Jistým řešením může být vhodné rozdělení datasetu a paralelně tarovat jeho různé části. Ovšem ne vždy je toto možné udělat.