
Pokračujeme v příběhu [1] [2] o pomalém ZFS na FreeBSD. Tentokrát se podíváme na to, co jsou to malé soubory z hlediska rychlosti čtení ZFS.
Hlavní dva parametry rotačního disku, které ovlivňují rychlost čtení z disku, jsou:
- Rychlost otáčení (rpm) určující kolik bloků za sekundu je disk schopen přečíst. Během čtení náhodně umístěných bloků je disk schopen přečíst jeden blok (4kiB) za jednu otáčku disku. Tedy pro 7200rpm disk platí, že rychlost čtení náhodných bloků je 7200 / 60 = 120 * 4kiB = 480 kiB. Toto je tedy nejnižší rychlost čtení, které je disk schopen dosáhnout.
- Sekvenční rychlost, ta je určena především hustotou záznamu dat na disku a obvodovou rychlostí disku. Dnešní disky mohou číst rychlostí začínající na 200MB/s, ale pozor, čím více ke středu disku, tím rychlost klesá a může klesnout až někam k 60MB/s podle typu disku.
Je tedy jasné, že čím menší soubory čteme, tím nižší bude rychlost čtení. Ale jak nízká? Pro opravdu malé soubory (např. maildir) nelze očekávat více než 480kiB/s a to ještě za předpokladu, že jsou dopředu načtené inode (informace o umístění bloků na disku). Pokud nejsou a pro každý čtený soubor je potřeba ještě přečíst jeho inode, tak efektivní rychlost může klesnout na polovinu, tedy někam k 200kiB/s. S tímto se skutečně mnoho dělat nedá. Některé FS problematiku malých (ale opravdu malých na úrovni desítek B), řeší tak, že je umísťují přímo do adresářového záznamu, data souborů se tedy dostanou do cache už při načtení adresáře a další výlety na disk nejsou potřeba.
U souborů o velikosti 1MiB lze teoretickou očekávanou rychlost čtení vypočítat. Víme, že disk umí 200MiB/s, 1MiB se čte 5ms. Seek (otáčka disku) mezi soubory je 8.3ms. Na jeden 1MiB soubor je tedy potřeba 13ms. To je 75 souborů za 1s. Tedy 75MiB/s. Připustíme-li, že pro každý soubor je potřeba ještě jeden extra výlet do inode, vyjde nám teoretická rychlost 46 souborů / s (46 MiB/s).
Jaká je praxe? Napsal jsem si jednoduchý skript, který rozdělí soubory v datasetu podle jejich velikosti (jedná se o reálné soubory, proto nebylo možné filtrovat na přesnou velikost 1MB, 2MB apod. takže se jedná o skupiny souborů o velikosti vždy v nějakém rozmezí) a tyto soubory jsem z disku četl. V grafu je uvedena průměrná rychlost čtení souborů v daných skupinách.
První dataset je stejný, jaký jsem používal u testů v minulých článcích a obsahuje spíše malé soubory o velikosti do 20MB maximálně.
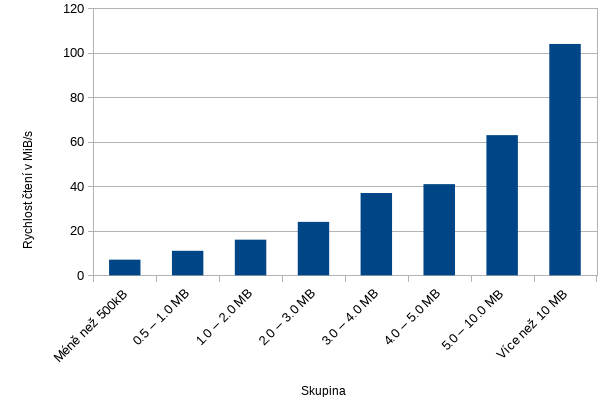
Rychlost čtení těch nejmenších souborů je bez překvapení, ale rychlost čtení skupiny kolem 1MB je 11 – 16MB/s. Tedy 3x až 7x pomaleji, než nám dal teoretický výpočet. Připomínám, že se jedná o zpool se třemi mirrory, tedy celkem 6 disků. Zpool by se měl chovat jako RAID10, ale v takovém případě bychom mohli očekávat zcela jiný výkon, který se nám ovšem nedostává. K očekávaným rychlostem kolem 70MB/s se dostáváme až u souborů o velikosti cca 5MB. Ani čtení souborů o velikostech nad 10MB nedosahuje nijak slavných rychlostí. Stále jsme na 25% výkonu tohoto zpoolu.
Druhý dataset obsahuje soubory o velikostech typicky desítky MB. Do grafu jsem záměrně umístil i předchozí výsledky, tento větší dataset tedy začíná od skupiny 10-20MB:
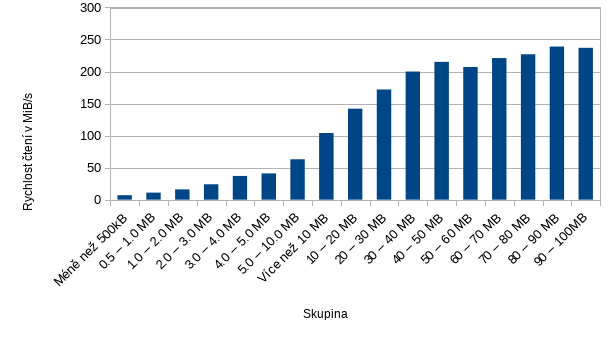
Jak vidíme, nějaké saturace rychlosti se dosahuje až někde kolem velikostí souborů 50 MiB. Vše menší se dá z hlediska tohoto ZFS považovat za malé soubory, protože nedosahuje ani teoretických rychlostí ani saturace. I při tomto testu se vytížení disků (iostat -x) pohybuje kolem 30-40%. Skutečně velké soubory tento zpool umí číst a za zapisovat rychlostmi kolem 400MB/s.
Čím to je fakt netuším. Jak jsem psal minule, systém se chová OK a velmi plynule a celé to na mě dělá dojem, že je tam někde skutečně „sleep“ na několik ms jako obrana proti zahlcení IO. Na druhou stranu tyto výsledky poskytují návod, jak k tomu FS přistupovat. Pro program je ideální data ukládat agregovaná do větších celků o velikostech cca 100MB. Například pro archiv emailů se hodí dovecot formát mdbox, který ukládá zprávy do souborech o velikosti max 10MB. Na komprimovaném datasetu tak lze dosáhnout skutečně efektivního uložení archivu emailů (stovky tisíc zpráv v několika málo rozumně velkých souborech o celkové velikosti pár GB, místo stovek tisíc jednotlivých maildir souborů).